Warum Code das neue No-Code für Maschinen- und Produktionsdaten ist

Maschinendaten sind heute fast überall verfügbar, doch wirklich nutzbare Analytik ist in der Praxis noch immer überraschend schwierig. Die meisten Unternehmen erfassen bereits Daten aus SPSen, Sensoren, Prüfstationen und Produktionssystemen. Die eigentliche Herausforderung beginnt aber einen Schritt später: Wie werden aus diesen Rohdaten Analysen, die wirklich erklären, was in der Fertigung passiert?
Über viele Jahre hinweg hat die Industrie versucht, dieses Problem mit No-Code-Werkzeugen zu lösen. Das war naheliegend: Wenn Ingenieure und Prozessexperten Analysen modellieren können, ohne selbst Software zu schreiben, kommen Projekte schneller voran und die Abhängigkeit von zentralen IT-Teams sinkt.
Doch genau hier zeigt sich auch die Grenze. Je spezifischer ein Produktionsprozess und je individueller die Fragestellung wird, desto starrer wirken viele klassische No-Code-Ansätze. Und gerade in der Fertigung sind Anwendungsfälle fast nie generisch.
Warum Maschinen- und Produktionsdaten schwer zu analysieren sind
Analytik auf industriellen Daten ist kein einzelnes Problem, sondern eine ganze Klasse sehr unterschiedlicher Fragestellungen, zum Beispiel:
- Welche Maschinenzustände treten besonders häufig auf und wie lange dauern sie?
- Welche Alarme haben den größten Einfluss auf Stillstände?
- Wie stabil ist der Output über die Zeit?
- Wo weichen Zyklus- oder Taktzeiten vom erwarteten Verhalten ab?
- Wie lässt sich ein Produkt über mehrere Stationen und Bearbeitungsschritte hinweg nachverfolgen?
Diese Fragen klingen zunächst einfach, die zugrundeliegenden Daten sind es in der Regel aber nicht. SPS-Daten sind in erster Linie für die Steuerung der Maschine gedacht und nicht für spätere Analysen. Signale sind aus Sicht der Automatisierung benannt, Ereignisse verteilen sich oft auf unterschiedliche Strukturen und die eigentliche fachliche Bedeutung entsteht meist erst dann, wenn mehrere Datenpunkte zusammengeführt werden.
Mit anderen Worten: Die Daten sind da, aber sie sind selten direkt analysefähig.
Daraus ergeben sich in der Praxis fast immer zwei wiederkehrende Herausforderungen:
- Verstehen des Datenmodells: Anwender müssen wissen, welche Tags, Events und Strukturen für einen konkreten Use Case relevant sind.
- Harmonisierung der Daten: Rohsignale aus Maschinen müssen meist erst in eine fachlich sinnvolle analytische Struktur überführt werden, bevor KPIs, Diagramme oder Berichte wirklich belastbar sind.
Genau deshalb war Fertigungsanalytik lange Zeit entweder ein Thema für individuelle Softwareprojekte oder für hochspezialisierte interne Teams.
Das Versprechen und die Grenze von No-Code
Self-Service-Analytik ist vor allem deshalb so attraktiv geworden, weil individuell entwickelte Lösungen nicht gut skalieren. Sie sind teuer, schwer anpassbar und in vielen Fällen aufwendig zu warten, sobald sich Prozesse oder Anlagen ändern.
No-Code- und Low-Code-Werkzeuge haben diese Situation deutlich verbessert. Grafische Pipelines, Drag-and-Drop-Regeln und wiederverwendbare Bausteine machen es möglich, analytische Logik sehr viel schneller zusammenzustellen. Plattformen wie Node-RED oder auch der Pipeline-Editor von Bytefabrik.AI zeigen, dass sich viele Streaming- und Event-Use-Cases effektiv modellieren lassen, ohne mit einem leeren Code-Editor zu beginnen.
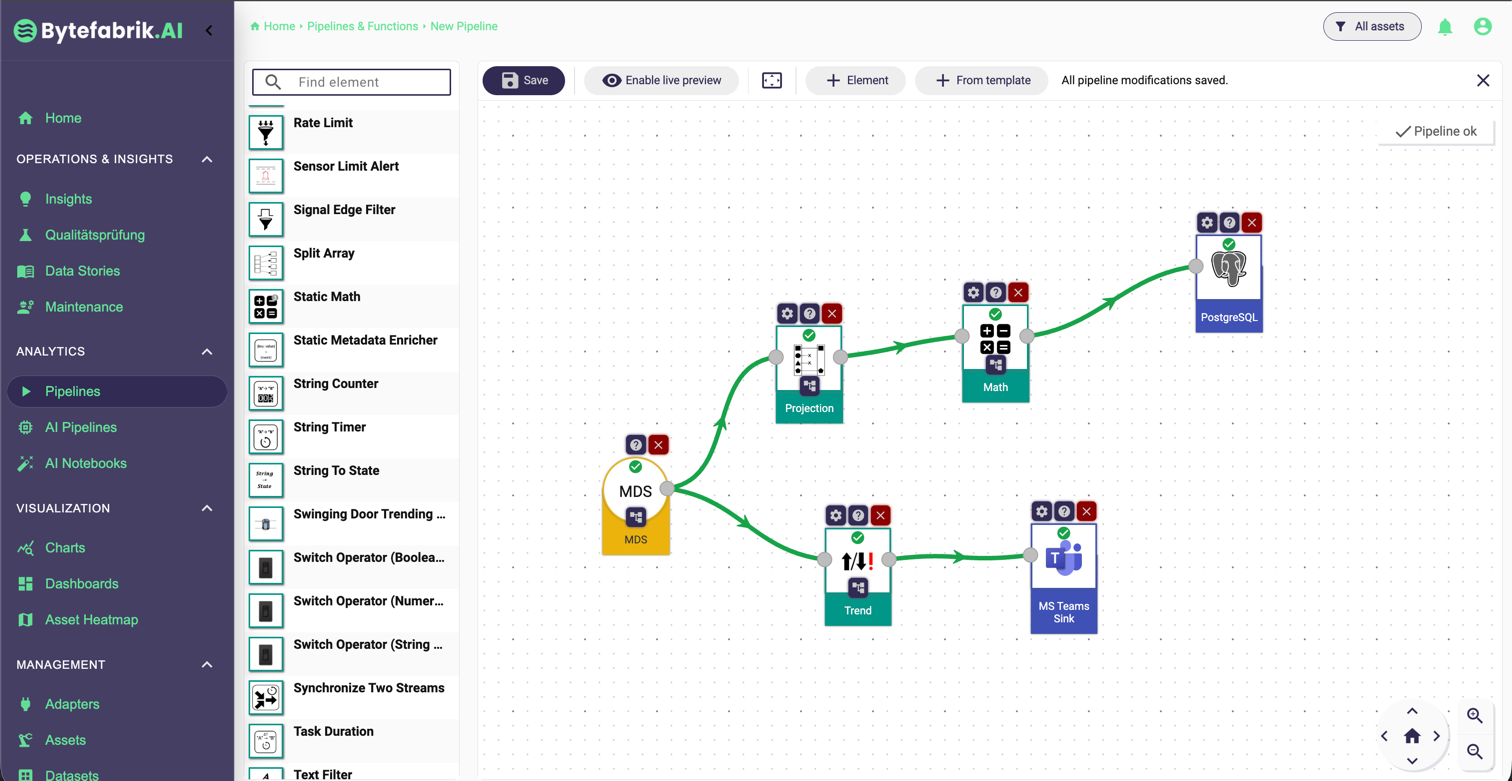
Das war ein wichtiger Fortschritt. Vorgefertigte Bausteine für Filter, Aggregationen, Schwellwertüberwachungen oder Trendanalysen senken die Einstiegshürde erheblich und beschleunigen viele wiederkehrende Aufgaben.
Gleichzeitig blieb der zentrale Zielkonflikt aber bestehen:
- Grafische Modelle sind leicht zugänglich, werden aber schwer wartbar, sobald die Logik komplexer wird.
- Hochspezifische Use Cases erfordern oft Verhalten, das sich nicht mit vorhandenen Bausteinen ausdrücken lässt.
- Flexibilität und einfache Bedienung stehen sich häufig direkt gegenüber.
Dieser Zielkonflikt hat die Datenanalyseplattformen über viele Jahre geprägt.
Warum Code zum neuen No-Code wird
Large Language Models und KI-Agenten verändern diese Gleichung grundlegend.
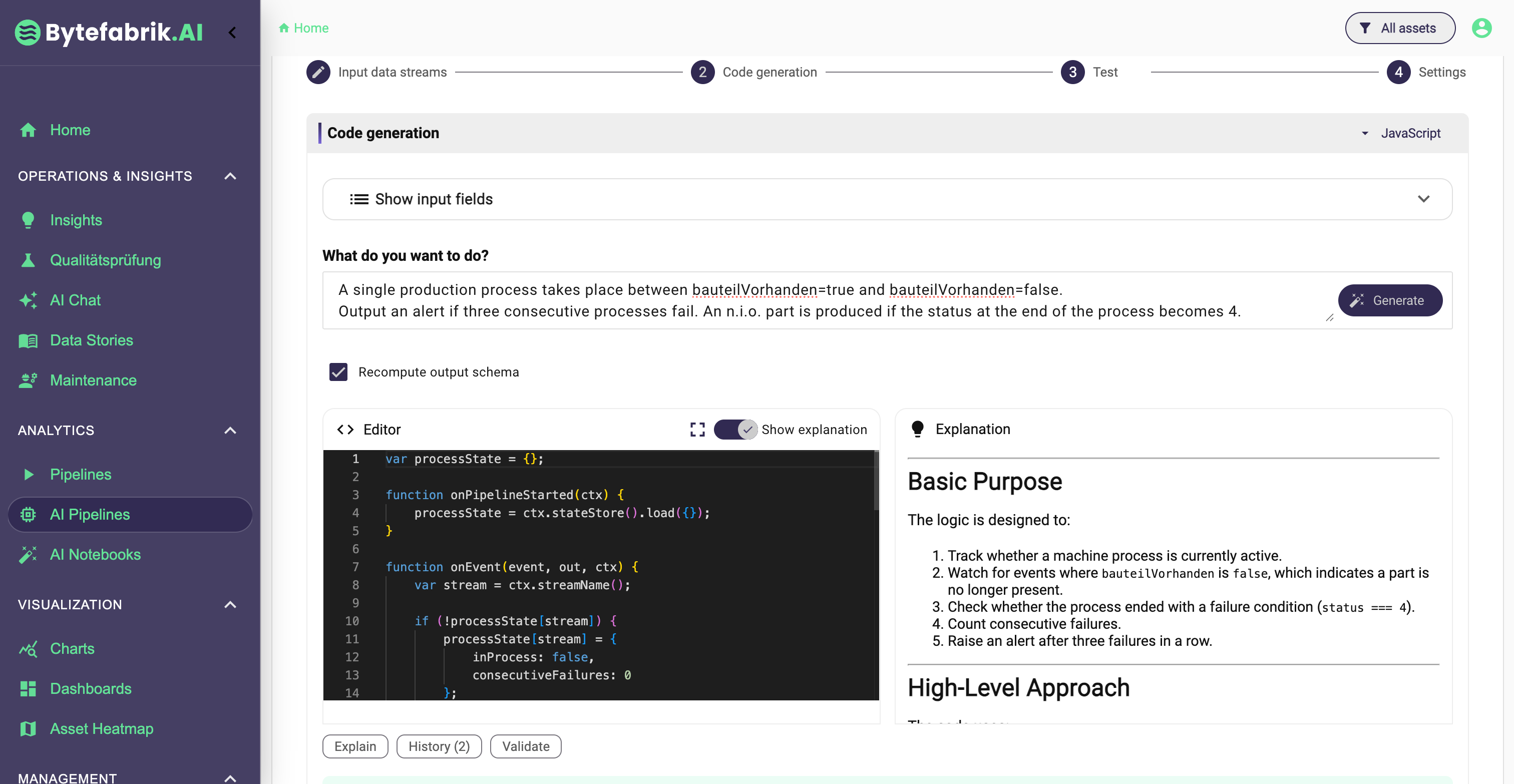
Zum ersten Mal können Anwender ein Analyseziel in natürlicher Sprache beschreiben und daraus direkt ausführbaren Code als Ausgangspunkt erzeugen lassen. Der entscheidende Unterschied ist nicht nur, dass Code generiert werden kann. Entscheidend ist, dass Code heute auch erklärt, getestet, verfeinert und iterativ verbessert werden kann, und zwar in einer Form, die für Domänenexperten praktisch nutzbar ist.
Das ist deshalb so relevant, weil Code schon immer die flexibelste Schnittstelle für Datenanalysen war. Wer mit Code arbeitet, muss nicht auf den nächsten visuellen Blocktyp oder auf ein Produktfeature warten. Transformationen, Korrelationen oder Kennzahlen lassen sich exakt so formulieren, wie der jeweilige Anwendungsfall es verlangt.
Bis vor kurzem hatte diese Flexibilität allerdings einen klaren Preis: Programmierkenntnisse. Dieser Preis ist heute deutlich gesunken.
KI-gestützte Entwicklung führt damit zu einem neuen Workflow:
- Ein Domänenexperte beschreibt den Anwendungsfall in natürlicher Sprache.
- Das System erzeugt daraus die analytische Logik als Code.
- Anwender können sich den generierten Code passend zu ihrem technischen und fachlichen Hintergrund erklären lassen.
- Das System kann Testdatenfälle erzeugen, um zu prüfen, ob der generierte Code den Zweck tatsächlich erfüllt.
- Der Code wird entweder direkt auf Live-Datenströmen oder auf historischen Daten ausgeführt.
- Das Ergebnis wird überprüft und in einer iterativen Schleife verfeinert.
- Das Resultat wird in Dashboards, Berichten oder in angebundenen Drittsystemen wie Benachrichtigungssystemen oder Datenbanken verwendet.
Genau deshalb wird Code zum neuen No-Code. Anwender arbeiten weiterhin auf einer hohen Abstraktionsebene, aber das Ausführungsmodell darunter ist nicht mehr auf ein geschlossenes visuelles System beschränkt. Es ist offen, ausdrucksstark und anpassbar.
Gerade für industrielle Analytik ist das ein großer Vorteil, weil Produktionsdaten selten so standardisiert sind, dass ein One-size-fits-all-Ansatz wirklich funktioniert. KI-generierter Code passt sehr viel besser zur Variabilität realer Maschinen, realer Prozesse und realer betrieblicher Fragestellungen.
Ein konkretes Beispiel: Ein Alarm-Log aus OPC-UA-Events erzeugen
Betrachten wir einen typischen Use Case aus der Praxis: die Analyse von Produktionsalarmen. Ein Unternehmen möchte verstehen, welche Alarme in einer Linie die größten Auswirkungen auf Störungen oder Stillstände haben. Als Rohquelle liegt ein OPC-UA-Event-Stream aus Maschinen oder Stationen vor.
Auf den ersten Blick klingt das einfach: Alarme erfassen und zählen. In der Praxis ist die Struktur deutlich komplexer.
OPC-UA-Events enthalten typischerweise Informationen wie:
- den Zeitstempel des Events;
- den Source Node oder Source Name;
- den Meldungstext;
- die Severity;
- den Active- oder Inactive-Status;
- den Acknowledge- oder Confirm-Status;
- zusätzliche Felder abhängig vom jeweiligen Event-Typ.
Damit diese Daten für Produktionsanalysen nutzbar werden, muss der Event-Stream in der Regel zunächst in ein fachlich sinnvolles Alarm-Log transformiert werden, zum Beispiel mit einer Struktur wie:
errorIdstartTimeendTimedurationseverityimpactassetoderstation
Schon genau diese erste Transformation ist oft der Punkt, an dem Projekte ins Stocken geraten. Es braucht Logik, die erkennt, welche Events zusammengehören, wann ein Alarm beginnt, wann er endet, wie wiederholte Events zusammengeführt werden und wie sich Severity in einen betrieblichen Impact übersetzen lässt. Und wenn eine andere Maschine statt OPC-UA-Events ein proprietäres Modell verwendet, zum Beispiel Fehler als Bitfelder bereitstellt, beginnt der Aufwand zur Harmonisierung der Rohdaten praktisch von vorn.
Genau für diese Art von Aufgabe ist KI-gestützte Codegenerierung deutlich besser geeignet als starre No-Code-Blöcke. Ein Anwender kann das gewünschte Alarmmodell in natürlicher Sprache beschreiben, die Transformationslogik automatisch erzeugen lassen und Details wie Gruppierungsregeln, Laufzeitberechnung oder Impact-Bewertung anschließend iterativ verfeinern.
Sobald das Alarm-Log vorliegt, werden die nachgelagerten Analysen deutlich einfacher:
- Welche Alarme verursachen die meiste Stillstandszeit?
- Welche Stationen haben die höchste Alarmfrequenz?
- Gibt es Alarme, die regelmäßig vor Qualitätsproblemen auftreten?
- Welche Alarme sind nur Rauschen und welche sind wirklich betriebskritisch?
Die eigentliche Schwierigkeit liegt nicht im Dashboard. Die Schwierigkeit liegt darin, aus rohen Maschinenereignissen und dem daraus abgeleiteten Alarm-Log die richtige analytische Repräsentation zu erzeugen.
Von statischen Werkzeugen zu iterativer Analytik
Eine weitere wichtige Veränderung ist, dass KI Code nicht nur einmalig erzeugt. Sie kann einen iterativen Analyseprozess unterstützen.
Wenn das erste Ergebnis noch nicht ausreicht, können Anwender gezielt nachschärfen:
- "Teile die Alarmdauern nach Stationen auf."
- "Ignoriere Wartungsmodus."
- "Korreliere hochschwere Alarme mit Ausschussteilen."
- "Zeige nur Alarme, die innerhalb von 30 Sekunden vor einem Stopp auftreten."
Dieser Workflow kommt der tatsächlichen analytischen Arbeit sehr nahe. Erkenntnisse entstehen nur selten nach einer einzigen Dashboard-Konfiguration. Sie entstehen durch Verfeinerung, Umformulierung und das wiederholte Prüfen von Annahmen.
Genau deshalb fühlt sich KI-gestützte, codebasierte Analytik in der Fertigung so natürlich an. Anwender müssen nicht zuerst in Softwareimplementierungen denken. Sie können in Prozessverhalten, Maschinenereignissen und operativen Fragestellungen denken.
Unser Ansatz bei Bytefabrik
Bei Bytefabrik setzen wir diese Idee in zwei sich ergänzenden Bausteinen um.
AI Pipelines sind für Live- und operative Szenarien gedacht. Sie helfen Anwendern dabei, Alerting-Regeln, eventbasierte Logik und On-the-fly-Analysen auf Streaming-IoT-Daten umzusetzen. Anstatt Nutzer auf einen festen Satz visueller Bausteine zu begrenzen, kann KI den Code für spezialisierte Transformationen und Auswertungen automatisch erzeugen.
AI Notebooks adressieren die historische Analyse. Sie kombinieren native Python-Unterstützung, wobei wir auf dem bestehenden offenen Python-Client aufbauen, der mit unserer Kernplattform interagiert, mit KI-gestützter Codegenerierung und interaktiven Visualisierungskomponenten. Dadurch lassen sich Produktionsdaten flexibel, reproduzierbar und ohne Toolwechsel untersuchen. Das ist besonders wertvoll für Root-Cause-Analysen, Qualitätsanalysen, Trendbewertungen oder Alarm-Mining.
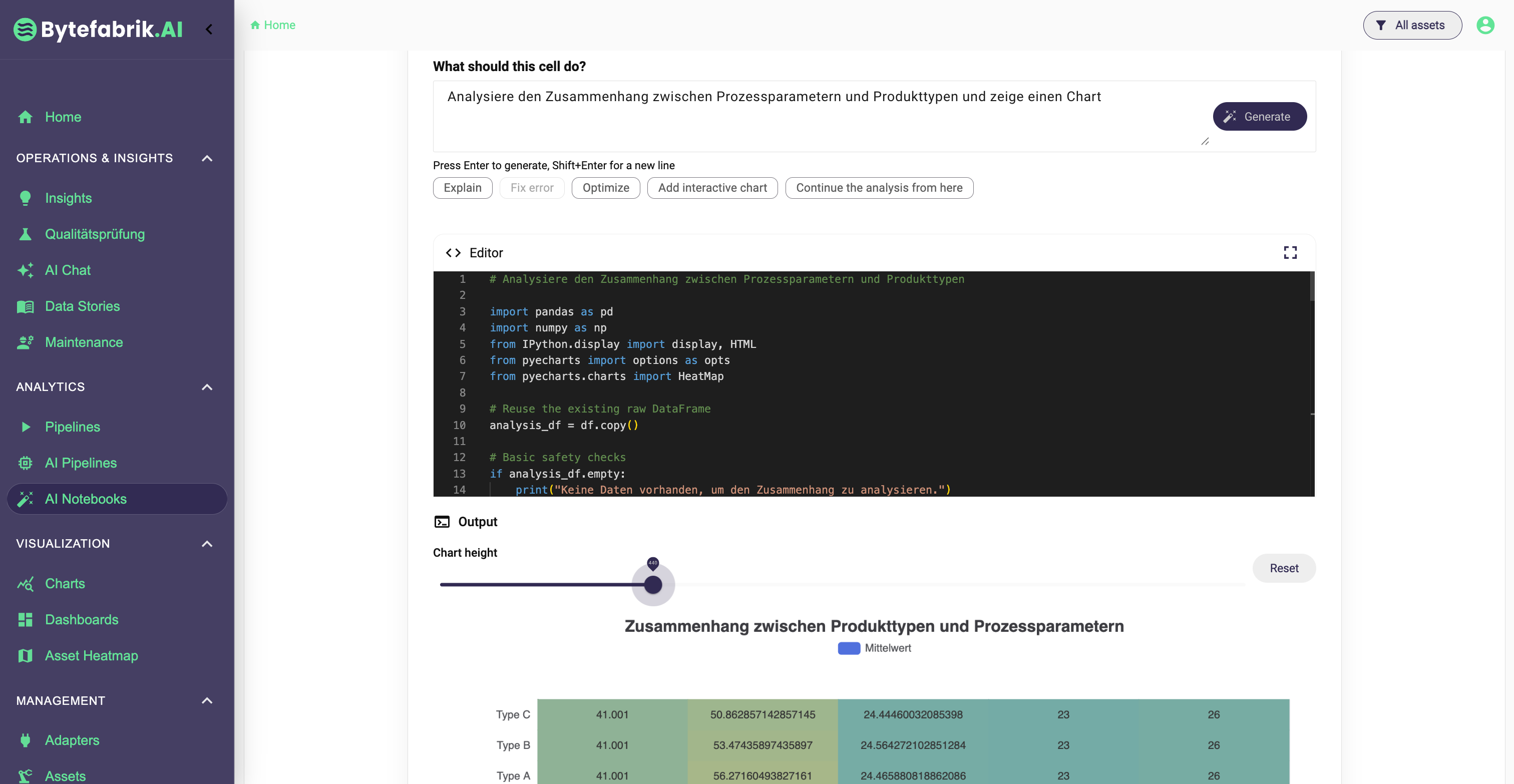
In beiden Werkzeugen haben wir fortgeschrittene KI-Methoden integriert, um sicherzustellen, dass generierter Code korrekt, nachvollziehbar und ausführbar ist.
Gemeinsam decken beide Ansätze die zwei zentralen Seiten industrieller Analytik ab:
- unmittelbare operative Reaktionen auf Live-Daten;
- tiefgehende Analysen auf historischen Maschinen- und Produktionsdaten.
Das größere Bild
Die Demokratisierung von Maschinen- und Produktionsdatenanalysen bedeutet nicht, jede technische Tiefe zu entfernen. Sie bedeutet, diese Tiefe zugänglich zu machen, wenn sie gebraucht wird, ohne jeden Anwender zum professionellen Softwareentwickler machen zu müssen.
Früher haben No-Code-Werkzeuge den Zugang demokratisiert, indem sie Code verborgen haben. Heute demokratisiert KI den Zugang, indem sie Code nutzbar macht.
Das ist ein kleiner sprachlicher Unterschied, fachlich aber ein sehr großer. Denn dadurch bleibt Flexibilität erhalten, statt sie durch zusätzliche Abstraktion zu ersetzen. Und genau diese Flexibilität entscheidet in industriellen Umgebungen häufig darüber, ob aus einer guten Demo auch ein System mit echtem operativem Nutzen wird.
Maschinen- und Produktionsdatenanalytik tritt damit in eine neue Phase ein. Erfolgreich werden die Plattformen sein, die Domänenexperten mit möglichst wenig Reibung und zugleich mit maximaler Kontrolle von rohen Maschinenevents zu belastbaren Erkenntnissen bringen.
Wenn Sie sehen möchten, wie AI Pipelines und AI Notebooks das in der Praxis ermöglichen, werfen Sie einen Blick auf unsere AI Notebooks, AI Pipelines oder vereinbaren Sie eine Demo.